Replication Package of Generating Concept based API Element Comparison Using a Knowledge Graph
Empirical Study
Data Prepare
-
1487 candidate questions.To retrieve questions about API comparison, we selected questions from the Stack Overflow data dump. 1487 candidate questions from the Stack Overflow had either of the strings “difference between” or “vs” in the title. In the file, “Id” represent Stack Overflow post ID, “Title” represent Stack Overflow question title, “Score” represent Stack Overflow question vote.
-
1487 candidate questions annotated result. The manual removal was conducted by two students independently (one PhD and one MS student, both with more than five years Java experience), this is 1487 candidate questions two students independently annotated result. In this excel file, the column “Stack Overflow Post ID” represents the post ID in Stack Overflow. And the column “User 1”, “User 2”, represents two students annotated result, “T” means that question is related to the JDK API comparison, “F” means not.
-
215 API class/method comparison questions. We only kept questions that had been annotated as relevant by both students, resulting in 215 questions. In this excel file, the column “id” represents post ID in Stack Overflow, “title” represents the Stack Overflow question title, “url” represents corresponding Stack Overflow URL, “question_vote” represents the Stack Overflow question votes when we got.
-
100 API comparison questions out of the 215 questions. 115 unselect questions. We randomly selected 100 API comparison questions out of the 215. In the excel files, the column “id” represents post ID in Stack Overflow, “title” represents the Stack Overflow question title, “url” represents corresponding the Stack Overflow URL, “question_vote” represents the Stack Overflow question votes when we got.
Empirical Study Data
-
Where answer point can be found in API document for 100 selected API comparison questions?. In this excel file, in the column “class or method”, “M” represents Method, “C” represents Class/Interface, column “answer point” is atomic answer point, column “Compare APIs” is all APIs involved in one answer point, “Is this information available in some form in the API documentation? yes/no” means whether we can infer answer point from JDK documentation. “Which API documentation page contained this information?” means all places we can find, “where in API doc?first sentence of class/first paragraph of class/full text of class/class hierarchical structure/class declaration/first sentence of method/full text of method/method declaration” record where we can find. “statements in API doc?” record which statement we infer this answer point.
-
Statement types classification result of 255 answer point, classify 255 answer points into eight statement types, in this excel file, in the column “Statement Type”, answer point can be classified into eight types.
Evaluation
RQ4 Related Data
JDK API Knowledge Graph Construction Experiment
-
Three aspects extracted statements integration data. Randomly selected 384 API statements for each of the three aspects (i.e., category, functionality, characteristic) and each of the two sources, this file shows the labeled and arbitrate result. In the sheet “func_text_relation”, “func_name_relation”, “character_text_relation”, “character_name_relation”, “category_text_relation”, “category_name_relation” represent 384 API statements of functionality extracted from the text,384 API statements of functionality extracted from API name, 384 API statements of characteristic extracted from text, 384 API statements of characteristic extracted from API name or API structure,384 API statements of category extracted from text,384 API statements of category extracted from API name or API structure respectively. The column “s_name” means start name, “e_name” means end name, “r_name” is the relation name, column “other_info” show where we extract this API statement. column “user 1 T/F”, “user 2 T/F”, “judge T/F” means whether user 1/ user 2/arbiter labeled the extract statement is valid, “T” for valid, “F” for invalid.
-
Equal/opposite characteristics label result, there are 3 sheets, “user_1” sheet is the first student labeled result, “user_2” sheet is the second student labeled result, the column “start” means the start name in relation tuple, “end” means the end name in relation tuple, “relation” means the relation name, result means whether the extract statement is valid, “T” for valid, “F” for invalid.
-
Noun concept categorization, there are 3 sheets, “user_1” sheet is the first student labeled result, “user_2” sheet is the second student labeled result, the column “start” means the start name in relation tuple, “end” means the end name in relation tuple, “relation” means the relation name, result means whether the extract statement is valid, “T” for valid, “F” for invalid.
-
General concept linking result. In this excel file, “wd_item_id” means the wikidata website ID, “arbitrate judgeT/F” is arbitrate result, “T” for valid, “F” for invalid.
Android API Knowledge Graph Construction Experiment
-
Three aspects extract statements integration data. Randomly selected 384 API statements for each of the three aspects (i.e., category, functionality, characteristic) and each of the two sources, this file shows the labeled and arbitrate result. In the sheet “func_text_relation”, “func_name_relation”, “character_text_relation”, “character_name_relation”, “category_text_relation”, “category_name_relation” represent 384 API statements of functionality extracted from the text,384 API statements of functionality extracted from API name, 384 API statements of characteristic extracted from text, 384 API statements of characteristic extracted from API name or API structure,384 API statements of category extracted from text,384 API statements of category extracted from API name or API structure respectively. The column “s_name” means start name, “e_name” means end name, “r_name” is the relation name, column “other_info” show where we extract this API statement. column “user 1 T/F”, “user 2 T/F”, “judge T/F” means whether user 1/ user 2/arbiter labeled the extract statement is valid, “T” for valid, “F” for invalid.
- Equal/opposite characteristics label result. There are 3 sheets, “user_1” sheet is the first student labeled result, “user_2” sheet is the second student labeled result, the column “start” means the start name in relation tuple, “end” means the end name in relation tuple, “relation” means the relation name, result means whether the extract statement is valid, “1” for valid, “0” for invalid.
- Noun concept categorization, there are 3 sheets, “user_1” sheet is the first student labeled result, “user_2” sheet is the second student labeled result, the column “start” means the start name in relation tuple, “end” means the end name in relation tuple, “relation” means the relation name, result means whether the extract statement is valid, “T” for valid, “F” for invalid.
- General concept linking result. In this excel file, “wd_item_id” means the wikidata website ID, “arbitrate judgeT/F” is arbitrate result, “T” for valid, “F” for invalid.
RQ5 Related Data
JDK Effectiveness Evaluation
- Student 1, Student 2 Student 3 Student 4. Completeness and conciseness understandability score and answer point covered. There are 2 sheet, “base_line” sheet shows the result for baseline approach, “difference” sheet shows the result for APIComp. column “compare API_1” and “compare API_2” represent the two compare APIs, column “answer point” is how many answer point covered, column “concise” is concise score, column “complete” is completeness score, column “understandable” is understandability score.
- The coverage evaluation for APIComp and baseline result. In the “coverage” sheet, s1~s4 represent different student judgments base on APIComp or baseline method, “arbitration-“ means the arbitration results.
Android Effectiveness Evaluation
- We select question from 100 top-voted questions from Stack Overflow. There are two sheet, “top100” sheet shows the top 100 Android related Stack Overflow Question and label result. “consensus” show consensus results.
- Android answer point select result. There are 3 sheet, “s1” sheet, “s2” sheet, and “s3” sheet represent the answer point extract results of the first student, the second student, and consensus result respectively. The column “s1 result(1 for true,0 for false)” means the first student label result, the column “s2 result(1 for true,0 for false)” means the second student label result.
- API comparison service coverage result. In the “coverage” sheet, column “s1: found in APIComp (0 for false/1 for true)” represent the first student labeled result, column “s2: found in APIComp (0 for false/1 for true)” represent the second student labeled result, “Arbitration Results” represent the coverage arbitration results.
RQ6 Related Data
- Participants experience statistics. There are two sheet, “GA” and “GB”, indicates the two participant groups. the column “experience/year” represent the age of the participants using java.
- Participant Group A result, Participant Group B result. Divided participants into two “equivalent” groups (GA and GB). Randomly divided the 12 tasks into two groups (TA and TB), each with 3 class selection tasks and 3 method selection tasks. In these result files, column “tool/search engine” represent which method the participant use, column “answer (1-API_1, 2-API_2, 3-unknown)” represent which API the participant select, column “cost_time:” represent the total time cost to make the decision,the unit is seconds. Odd question are TA, even question are TB.
Example
Screen Shot
APIComp Tool screen shot
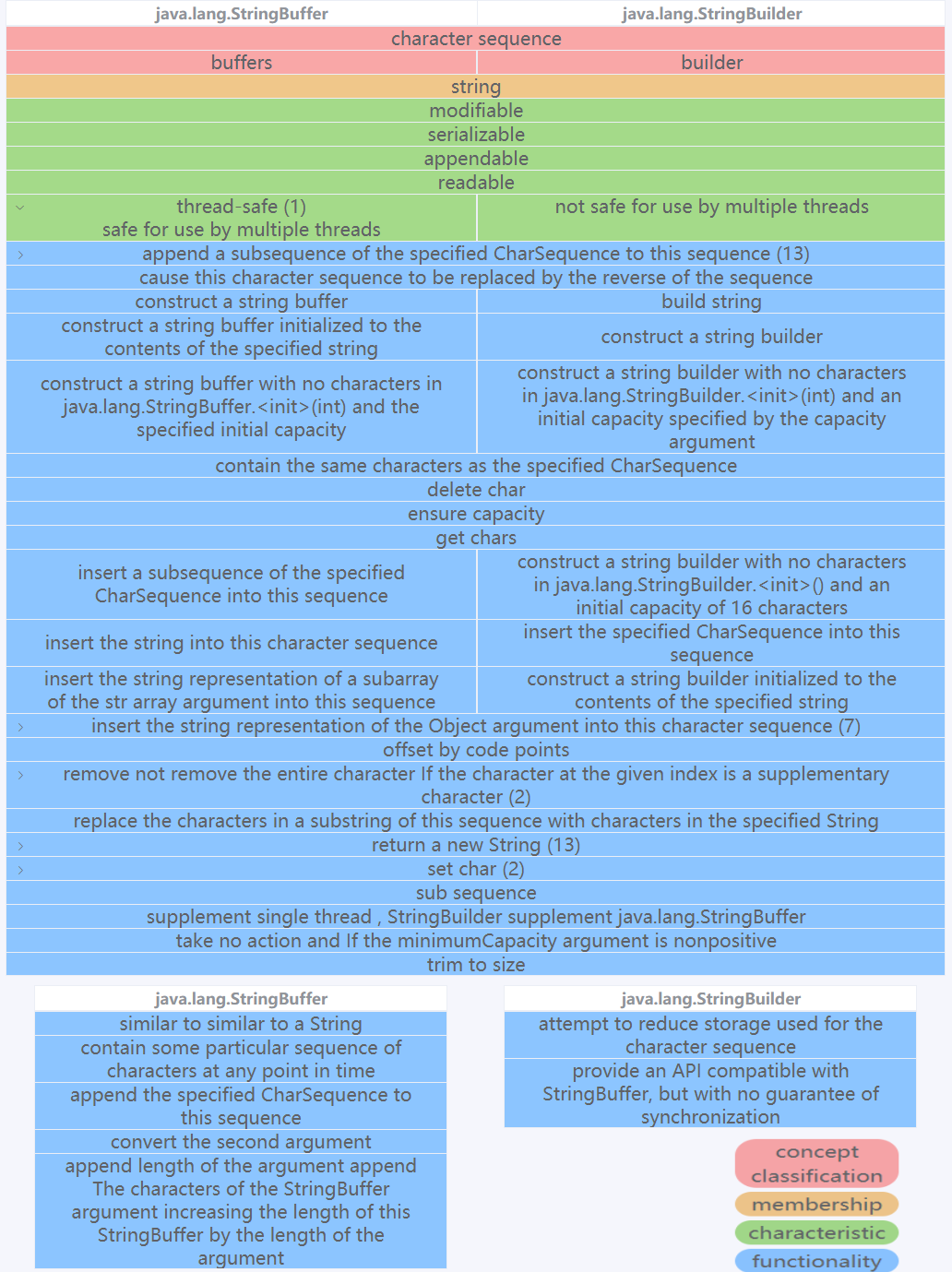
Baseline screen shot
